过拟合是指模型在训练集上表现很好,但在验证和测试阶段效果比较差,即模型的泛化能力很差。过拟合的解决方法如下。
(1)增加训练数据量。发生过拟合最常见的原因就是数据量太少或者模型太复杂,增加数据量可以缓解该问题,如在图像识别时,增加训练数据集的图像数量可以降低过拟合的风险。如果数据获取比较困难,可以将现有数据集上的图像进行旋转、拉伸等操作,从而实现数据集扩展。
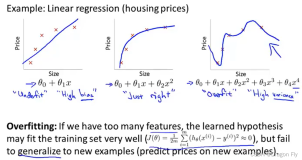
(2)减少数据特征,去掉数据中非共性的特征。
(3)调整超参数。
(4)使用正则化约束或者增强正则化约束。
(5)降低模型的复杂度。
(6)使用Dropout。Dropout只适用于神经网络,按照一定的比例失活隐藏层的神经元,使得神经网络更简单。
(7)Early Stopping,即提前结束训练。在训练模型的过程中,如果训练误差一直在降低,但是验证误差却不再降低甚至上升,这时候便可以结束模型训练。
过拟合
2024-07-25
115
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
【7月更文挑战第25天】过拟合。

目录
相关文章
|
7月前
|
机器学习/深度学习
算法
大模型开发:什么是过拟合和欠拟合?你如何防止它们?
机器学习中,过拟合和欠拟合影响模型泛化能力。过拟合是模型对训练数据过度学习,测试集表现差,可通过正则化、降低模型复杂度或增加训练数据来缓解。欠拟合则是模型未能捕捉数据趋势,解决方案包括增加模型复杂度、添加特征或调整参数。平衡两者需通过实验、交叉验证和超参数调优。
741
0
0
|
机器学习/深度学习
算法
|
4月前
|
机器学习/深度学习
|
5月前
|
人工智能
Python
模型评估与选择:避免过拟合与欠拟合
【7月更文第18天】在人工智能的探险旅程中,打造一个既聪明又可靠的模型可不简单。就好比在茫茫人海中找寻那位“知心朋友”,我们需要确保这位“朋友”不仅能在训练时表现优异,还要能在新面孔面前一样游刃有余。这就引出了模型评估与选择的关键议题——如何避免过拟合和欠拟合,确保模型既不过于复杂也不过于简单。今天,我们就来一场轻松的“模型相亲会”,通过交叉验证、混淆矩阵、ROC曲线这些实用工具,帮你的模型找到最佳伴侣。
209
2
2
|
7月前
|
机器学习/深度学习
|
机器学习/深度学习
算法
|
API
|
机器学习/深度学习
人工智能
计算机视觉
|
机器学习/深度学习
算法
|
机器学习/深度学习
人工智能
测试技术
热门文章
最新文章
1
手把手教你用Python实践深度学习
2
Maven之多模块打包成一个jar包及assembly
3
MS SQL 锁与事务
4
3D立方体图片切换动画
5
冒泡排序
6
应用的生命周期
7
11gR2 RAC ASM启动揭秘
8
Windows 8实用窍门系列:13.windows 8的文件.文件夹管理---2.文件以及文件夹操作
9
矿藏估价
10
如何查询全国各地公司有哪些股东(2017版)
1
「Mac畅玩鸿蒙与硬件43」UI互动应用篇20 - 闪烁按钮效果
38
2
转载:【AI系统】AI的领域、场景与行业应用
40
3
记录一次holo视图与物化视图的区别
35
4
Selenium IDE:Web自动化测试的得力助手
40
5
活动实践 | 西游再现,函数计算一键部署 Flux 超写实文生图模型部署
41
6
【实践】体验RDS通用云盘核心能力
24
7
活动实践 | 告别资源瓶颈,函数计算驱动多媒体文件处理测评
29
8
产品测评 | ECS的健康保障新助手——云服务诊断
34
9
如何构建媲美通义千问在线接口的qwen-max智能体
37
10
R中单细胞RNA-seq分析教程 (5)
27