什么是内存管理
内存管理是控制和协调应用程序访问电脑内存的过程。这个过程是复杂的,对于我们来说,可以说相当于一个黑匣子。
当咱们的应用程序运行在某个操作系统中的时候,它访问电脑内存(RAM)来达成下列几个功能:
- 运行需要执行的字节码(代码)
- 存储程序运行时候所需的数据
- 加载程序运行所需的运行时环境
上面用来存储程序运行时所需的数据,就是下面要说的堆(heap)和栈(stack)。
栈(stack)
顾名思义,是一种先进后出的结构,参考一下餐盘的取和放。
俄罗斯套娃,我这不禁
栈的特点
- 由于先进后出性质,在数据的处理上栈有着很好的速度,因为只需从最顶部压栈和出栈就好了,简单明了。
- 不过,存储在栈中的数据必须是大小有限,生存期确定。
- 函数执行的时候会创建一个明确的栈,并压入,而当执行期间会存储函数内的所有数据,这就是栈帧。个人感觉可以理解为当前执行函数的快照。
- 多线程应用程序有多个栈。
- 栈的操作系统自动分配或释放。
- 存储在栈中的常见类型有:局部变量(值类型、基本类型、常量)、指针和函数
- 还记得平常偶尔遇到的stack overflow error吗?这是因为与堆相比,栈的大小受到了限制。大多属语言都是都是这样。
堆(heap)
堆常用来动态内存分配,程序在堆中寻找数据需要使用指针。
堆的特点
- 效率不如栈,但是可以存储更多的数据
- 可存储大小不确定的数据,如运行时确定
- 应用程序中多线程共享堆数据
- 堆由人工操作,故管理起来很棘手,可能会引起内存泄漏等问题,所以有很多语言有gc机制
- 存储在堆中的常见类型有:全局变量、引用类型和其他复杂的数据结构
- 这就是为什么你会遇到out of memory errors这类问题,因为用户的胡乱分配或者未销毁
- 我们分配给堆的数据其实并没有大小限制,理论上来说你可以分配无穷大的数据。当然如果这样你也得为应用程序分配这么多的内存。 -_-
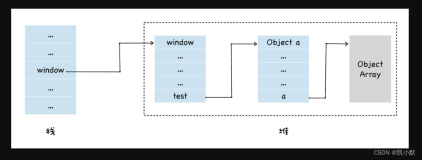
内存堆栈 与 数据结构堆栈的区别
| 内存 | 数据结构 | |
| 堆 | new一个对象的引用或地址存储在栈区,指向该对象存储在堆区中的真实数据。由程序员分配和回收 | 是一棵完全二叉树结构 |
| 栈 | 存储运行方法的形参、局部变量、返回值。由系统自动分配和回收。 | 是一种连续存储的数据结构,特点是存储的 |