Spark安装教程
1. 检查jdk版本
检查jdk是否安装并且版本是否为1.8
javac -version
# javac 1.8.0_171
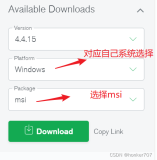
2. 获取Spark版本安装资源
本文以Spark3.1.2为例,资源详见文章上方。
https://dlcdn.apache.org/
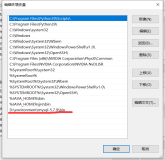
3.环境变量
vim /etc/profile
export SPARK_HOME=/opt/software/spark-3.1.2
export PATH=$SPARK_HOME/bin:$PATH
4.配置文件
cd $SPARK_HOME/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
------------------------------------------------
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop/
------------------------------------------------
cd $HADOOP_HOME/etc/hadoop
vim yarn-site.xml
------------------------------------------------
# 添加两个property
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
------------------------------------------------
5. 重启Hadoop集群(使配置生效)
stop-all.sh
start-all.sh
6. 启动Spark集群
/opt/software/spark-3.1.2/sbin/start-all.sh
6.1 查看Spark服务
jps -ml
----------------------------------------------------------------
1649 org.apache.spark.deploy.master.Master --host single --port 7077 --webui-port 8080
1707 org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://single:7077
----------------------------------------------------------------
6.2 访问Spark WEB UI
http://single01:8080/
7. 启动 Spark-Shell 测试 Scala 交互式环境
spark-shell --master spark://single:7077
----------------------------------------------------------------
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://single:4040
Spark context available as 'sc' (master = spark://single:7077, app id = app-20240315091621-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
scala> _
----------------------------------------------------------------
8. 测试Spark On Yarn
spark-shell --master yarn
----------------------------------------------------------------
Spark context Web UI available at http://single:4040
Spark context available as 'sc' (master = yarn, app id = application_1710465965758_0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
----------------------------------------------------------------
9.关闭Spark集群
/opt/software/spark-3.1.2/sbin/stop-all.sh