·摘要:
本文作者将CNN引用到了NLP的文本分类任务中。
·参考文献:
[1] Convolutional Neural Networks for Sentence Classification 论文链接:http://cn.arxiv.org/pdf/1408.5882.pdf
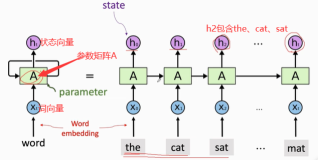
[1] 模型
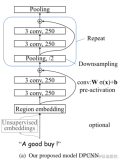
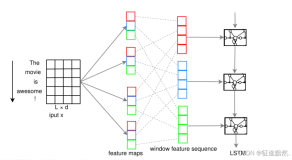
很基础的卷积神经网络模型。

算法流程:
1)word2vec词嵌入
将若干个文本中的所有词,进行无监督训练,得到词向量(word vectors)。对于每个文本,可以采用词向量加和、平均的方式表示。
2)convolutional卷积
卷积特征向量。
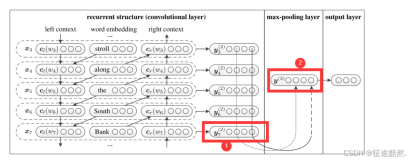
3)pooling池化
使用最大池化,抽取最重要的特征。
4)全连接
dropout规则化防止过拟合+ 全连接的softmax层多分类
[2] 模型参数
这里,模型根据词向量的不同分为四种:
· CNN-rand,所有的词向量都随机初始化,并且作为模型参数进行训练。
· CNN-static,即用word2vec预训练好的向量(Google News),在训练过程中不更新词向量,句中若有单词不在预训练好的词典中,则用随机数来代替。
· CNN-non-static,根据不同的分类任务,进行相应的词向量预训练。
· CNN-multichannel,两套词向量构造出的句子矩阵作为两个通道,在误差反向传播时,只更新一组词向量,保持另外一组不变。
[3] 实验结果

在七组公开数据集中进行,证明了:
· CNN在NLP文本分类中的有效性
· 通过调参,也表明了word2vec的NLP中重要意义。
[4] 拓展
1、入门了CNN,对torch、torchtext的使用有所掌握;
2、详细了解了在基于深度学习的文本分类任务中embedding层的作用,请阅读文章:【文本分类】深入理解embedding层的模型、结构与文本表示