
思路
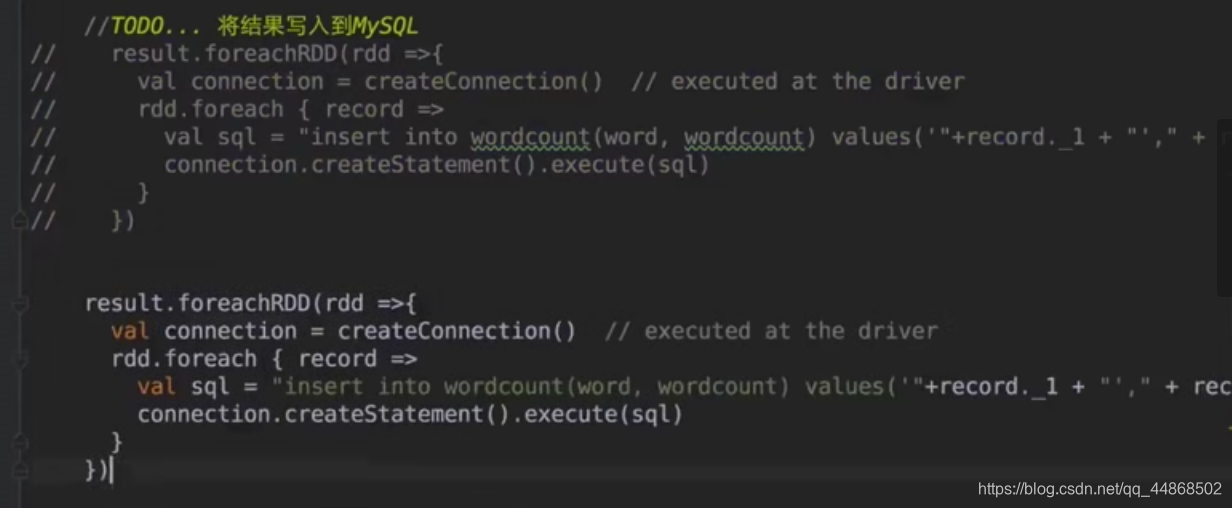
两种方式,一种可优化(foreachRDD后,直接创建连接Mysql),一种在(foreachRDD后通过foreachPartition,通过分区获取)
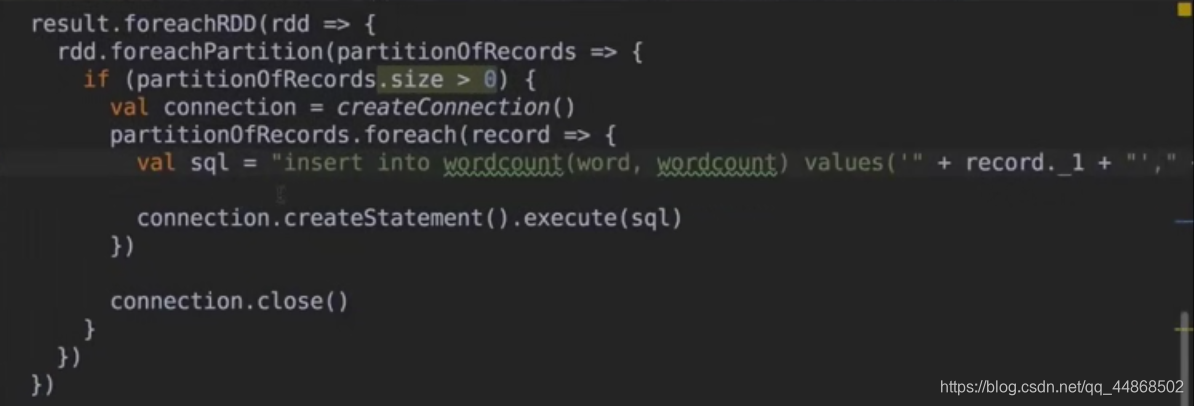
代码实现
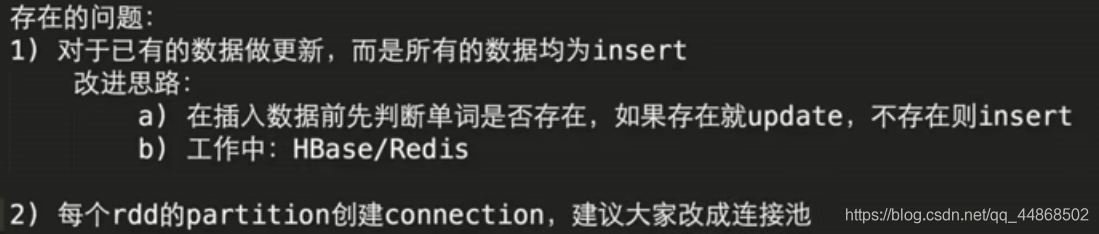
import java.sql.DriverManager import Spark.UpdateStateByKey.workds import Spark.WordCount.ssc import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} object MysqlByKey extends App{ val sparkConf = new SparkConf().setMaster("local[2]").setAppName("WordCount") val ssc = new StreamingContext(sparkConf,Seconds(10)) // 第一点,如果要使用updateStateByKey算子,就必须设置一个checkpoint目录,开启checkpoint机制 // 这样的话才能把每个key对应的state除了在内存中有,那么是不是也要checkpoint一份 // 因为你要长期保存一份key的state的话,那么spark streaming是要求必须用checkpoint的,以便于在 // 内存数据丢失的时候,可以从checkpoint中恢复数据 // 开启checkpoint机制,很简单,只要调用jssc的checkpoint()方法,设置一个hdfs目录即可 ssc.checkpoint("E:/test") // 实现基础的wordcount逻辑 val lines = ssc.socketTextStream("hadoop2", 9999) //val lines = ssc.textFileStream("E:/test") val words = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_) //将结果写入MySql words.foreachRDD(rdd => rdd.foreachPartition(line => { Class.forName("com.mysql.jdbc.Driver") //获取mysql连接 val conn = DriverManager.getConnection("jdbc:mysql://192.168.57.101:3306/test", "root", "1234") //把数据写入mysql try { for (row <- line) { val sql = "insert into wordcount(word,wordcount)values('" + row._1 + "','" + row._2 + "')" conn.prepareStatement(sql).executeUpdate() } } finally { conn.close() } })) /*方法二 words.foreachRDD(rdd=>{ rdd.foreachPartition(partionOfRecords=>{ if(partionOfRecords.size>0){ val connection = createConnection() partionOfRecords.foreach(record=>{ val sql = "insert into wordcount(word,wordcount) values("+record._1+","+record._2+")" connection.createStatement().execute(sql) }) connection.close() } }) }) //获取通过jdbc连接数据库 def createConnection()={ Class.forName("com.mysql.jdbc.Driver") DriverManager.getConnection("jdbc:mysql://hadoop2:3306/test","root","1234") }*/ words.print() ssc.start() ssc.awaitTermination() }
文章知识点与官方知识档案匹配,可进一步学







