
数据的分组,遍历,统计
俗话说:“人与类聚,物以群分”,到这里我们将学习数据的分组以及分组后统计。Pandas的分组相对于Excel会更加简单和灵活。
1️⃣分组
Pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。
✨效果

根据结果可以发现,分组后的结果为DataFrameGroupBy object,是一个分组后的对象。
用groupby的size方法可以查看分组后每组的数量,并返回一个含有分组大小的Series:
from pandas import Series,DataFrame # 创建二维列表存储选手信息 lol_list = [['上单','Nuguri',31,78], ['打野','Tian',42,68], ['中单','Doinb',51,83], ['中单','Faker',38,76], ['ADC','Lwx',74,72], ['辅助','Crisp',53,69]] # 创建dataframe df = DataFrame(data=lol_list, index=['a','b','c','d','e','f'], columns=['位置','ID号','年龄','数据']) groups = df.groupby('位置') print('----------------------------------')
✨效果

根据上面的方法,我们就能得到每个位置的占比了,别犹豫,在下面的代码框中一试便知。
for i,j in groups.size().items(): account = j/df.shape[0] dd="%.2f%%"%(account*100) print(f"{i}占比为{dd}") print(groups.size())
✨效果

df.groupby(‘位置’)是根据位置列对整个数据进行分组,同样我们也可以只对一列数据进行分组,只保留我们需要的列数据。
例如:我们通过位置,只对年龄列数据进行分组。
group = df['年龄'].groupby(df['位置']) # 查看分组 print(group.groups) # 根据分组后的名字选择分组 print(group.get_group('中单'))
✨效果

1.代码group = df['年龄'].groupby(df['位置'])
它的逻辑是:取出df中年龄列数据,并且对该列数据根据df[‘位置’]列数据进行分组操作。
2.上一步的代码也可改写成group = df.groupby(df['位置'])['年龄']
它的逻辑是:将df数据通过df['位置']进行分组,然后再取出分组后的年龄列数据。两种写法达到的效果是一样的。
3.group.groups的结果是一个字典,字典的key是分组后每个组的名字,对应的值是分组后的数据,此方法方便我们查看分组的情况。
4.group.get_group(‘中单’)这个方法可以根据具体分组的名字获取,每个组的数据
2️⃣对分组进行遍历
上面我们通过groupby()和size()两个方法以及以前所学的一些技能计算出了各位置的占比。
那如果我们想加入进去呢,我们可以根据年龄来判断,groups.get_group(‘中单’)可以获取分组后某一个组的数据,'中单’为组的名字,这样我们就可以对某一个组进行处理。
from pandas import Series,DataFrame # 创建二维列表存储选手信息 lol_list = [['韩国','上单','Nuguri',31,78], ['中国','打野','Tian',42,68], ['韩国','中单','Doinb',51,83], ['韩国','中单','Faker',38,76], ['中国','中单', 'xiye',21,45], ['中国','ADC','Lwx',74,72], ['中国','辅助','Crisp',53,69]] # 创建dataframes df = DataFrame(data=lol_list, index=['a','b','c','d','e','f','g'], columns=['国家','位置','ID号','年龄','数据']) group = df.groupby(df['位置'])['年龄'] # 查看分组 print(group.groups) # 根据分组后的名字选择分组 print(group.get_group('中单'))

通过上图我们可以得到中单的年龄,那么接下来我们就来算一算他们的平均年龄和最大最小年龄(这里样本数量较小,但是不影响操作)
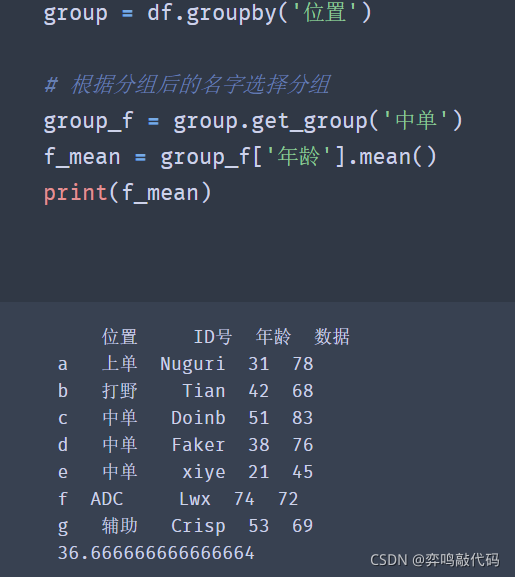
group = df.groupby('位置') # 根据分组后的名字选择分组 group_f = group.get_group('中单') f_mean = group_f['年龄'].mean() print(f_mean)
✨效果
🚩Pandas常用函数
| 函数 | 意义 |
| count() | 统计列表中非空数据的个数 |
| nunique() | 统计非重复的数据的个数 |
| sum() | 统计列表中所有数值的和 |
| mean() | 计算列表中的数据的平均值 |
| median() | 统计列表中的数据的中位数 |
| max() | 求列表中数据的最大值 |
| min() | 求列表中数据的最小值 |
其余的函数大家可以自行尝试
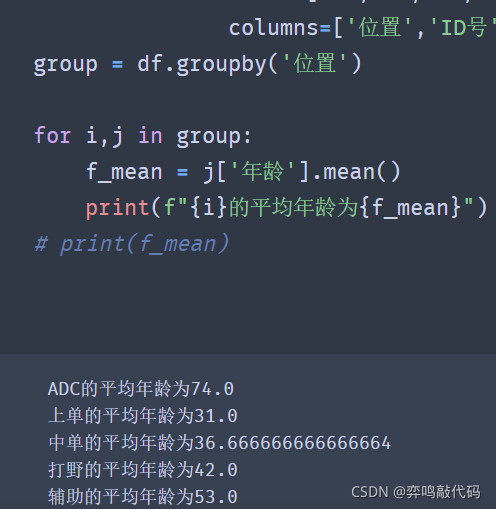
上面的代码成功的计算出了我们想要的数据,我们也可以遍历分组后的数据,并获取他们的最大年纪,最小年纪以及平均年龄。
group = df.groupby('位置') for i,j in group: f_mean = j['年龄'].mean() print(f"{i}的平均年龄为{f_mean}") # print(f_mean)
✨效果
3️⃣按多列进行分组
当我们需求更加的复杂时,若我们要对一组数据的对应的一个数据基础上划分,比如说我们要得到每个国家的位置的数量
按照上面的分析,难道我们要写两次groupby的分组操作?NO,我们强大的groupby()方法是支持按照多列进行分组。看下面
group = df.groupby(['国家','位置']) df1=group.size() print(df1)
✨效果
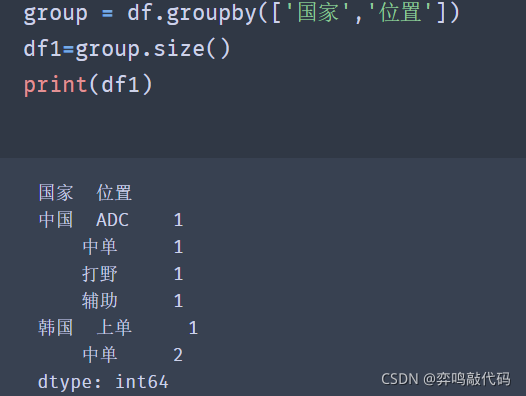
当需要按多列进行分组的时候,groupby方法里面我们传入的一个列表,列表中分别存储分组依据的列名。
注意:列表中列名的顺序,确定了先按国家列进行分组,然后再按位置列分组。不同的顺序,产生的分组名字是不同的。
那我们如何去获取里面的单个数据呢,group.size()返回的结果中发现索引值是多层的,那我们只需要一层一层的获取就行了
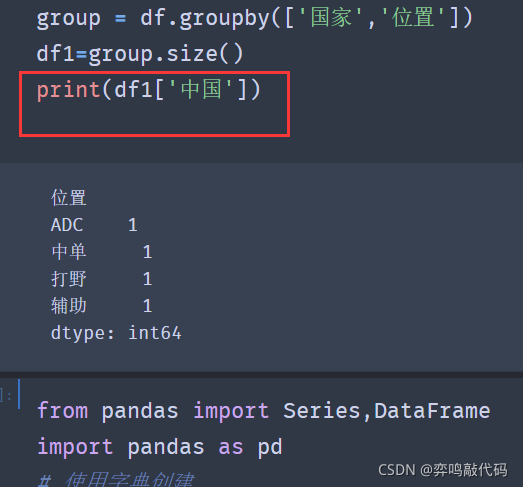
4️⃣对分组后数据进行统计
数据统计(也称为数据聚合)是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
pandas提供了一个 agg( )方法用来对分组后的数据进行统计。
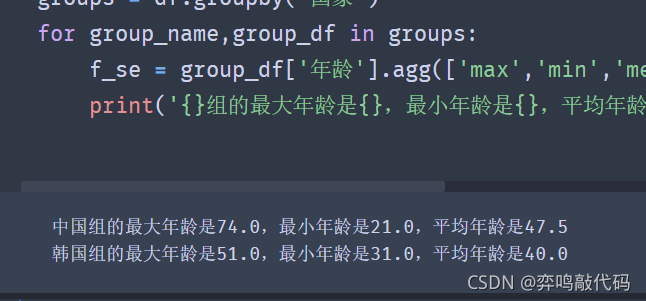
import pandas as pd df = pd.read_excel('data.xlsx') groups = df.groupby('gender') for group_name,group_df in groups: f_se = group_df['age'].agg(['max','min','mean']) print('{}组的最大年龄是{},最小年龄是{},平均年龄是{}'.format(group_name,f_se[0],f_se[1],f_se[2])) #注意:自定义的函数名字在传入agg()函数中时不需要转换成字符串。
观察上面的代码,可以发现在使用agg()函数时,我们可以将多个统计函数一起放到一个agg()函数中。
🚩并且需要注意的是,如果是统计函数是pandas提供的,我们只需将函数的名字以字符串的形势存储到列表中即可,例如:将max()改成'max'。
✨效果
这样不仅简化了我们的代码,在添加和删减统计函数的时候我们只需更改agg()函数中list就可以了。
它的好处还不止这些,比如现在又有新的需求,要计算年龄的最大值和最小值的差值。但是,pandas并没有提供这样统计函数,所以就需要我们进行自己定义一个统计函数:
def peak_range(df): """ 返回数值范围 """ return df.max() - df.min()
现在我们看一下自己定义的统计函数,如何使用
groups = df.groupby('国家') def peak_range(df): """ 返回数值范围 """ return df.max() - df.min() for group_name,group_df in groups: f_se = group_df['年龄'].agg(['max','min','mean',peak_range]) print(f'{group_name}组的最大年龄是{f_se[0]},最小年龄是{f_se[1]},平均年龄是{f_se[2]},最大值减去最小值{f_se[3]}')
