
2.读取hive写入HDFS
2.1工作流设计
工作流设计:
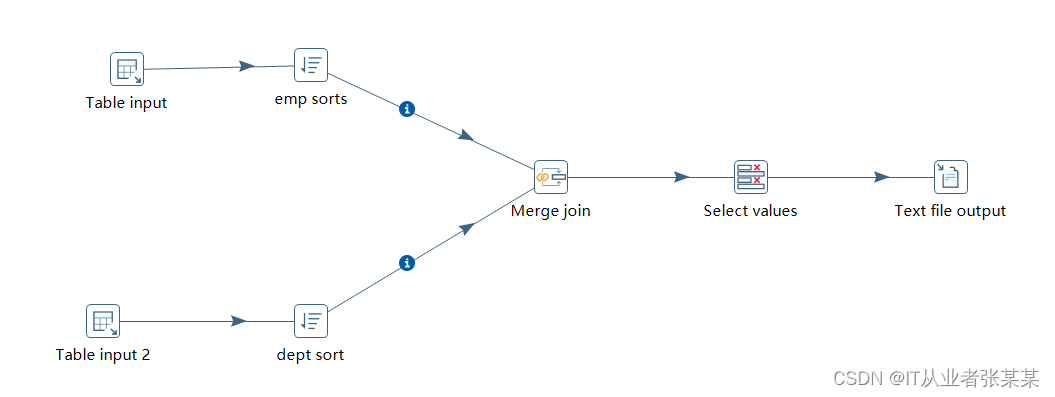
2.2 具体转换设计
具体步骤项如下:
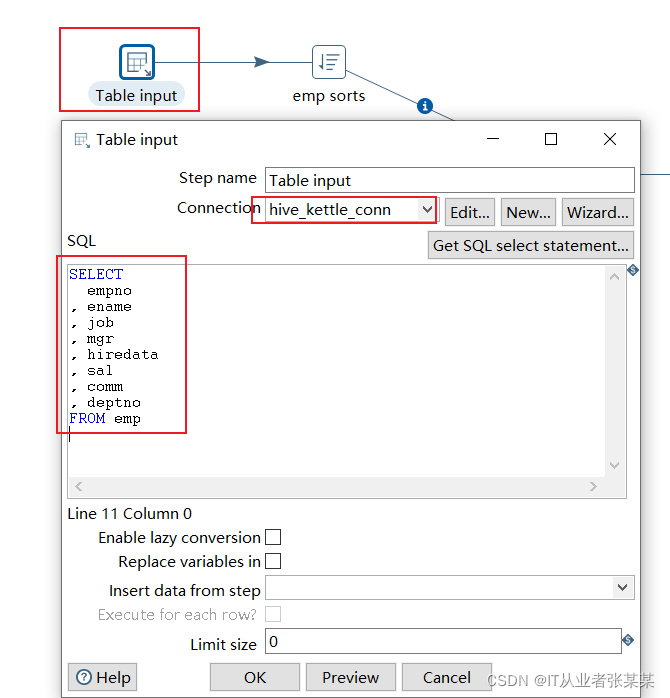
1)table input 步骤项设置
本步骤用于链接hive中的emp表,hive数据库链接如下:
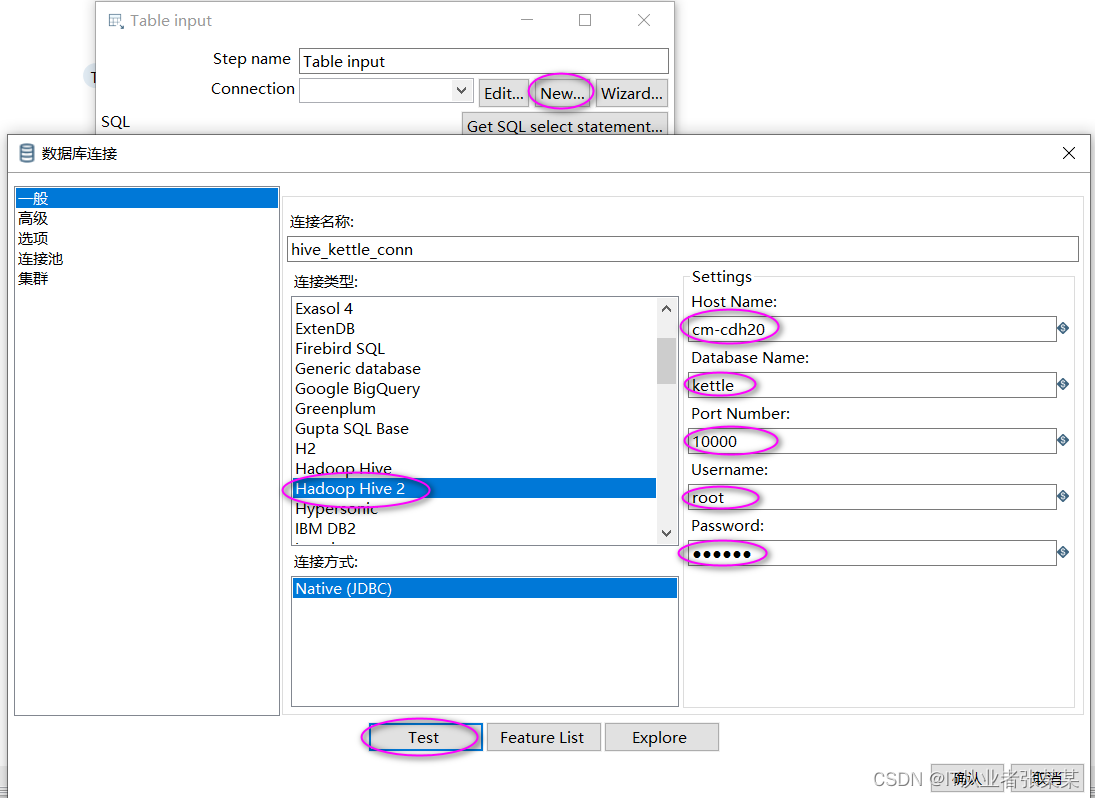
数据库操作sql语句如下:
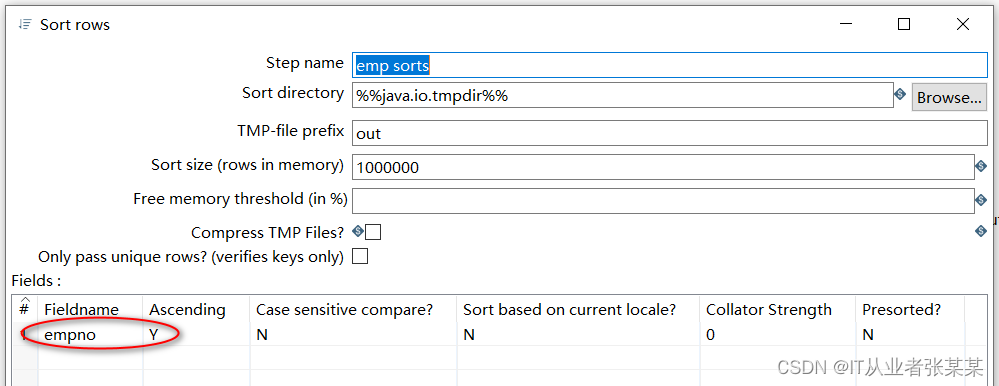
2)emp sorts 步骤项设置
本步骤用于对hive中的数据进行排序:
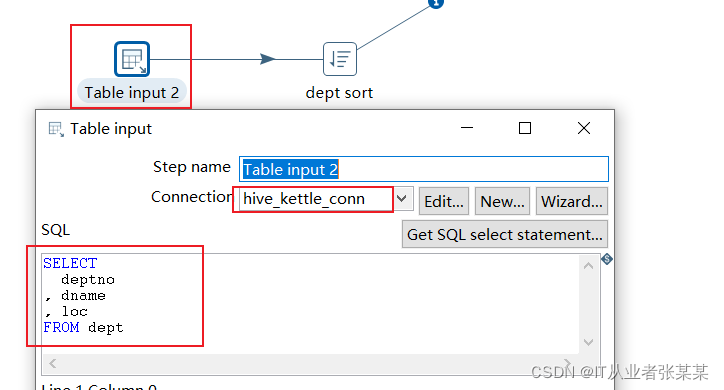
3)table input 2 步骤项设置
本步骤用于链接hive中的dept表,hive数据库链接如下:
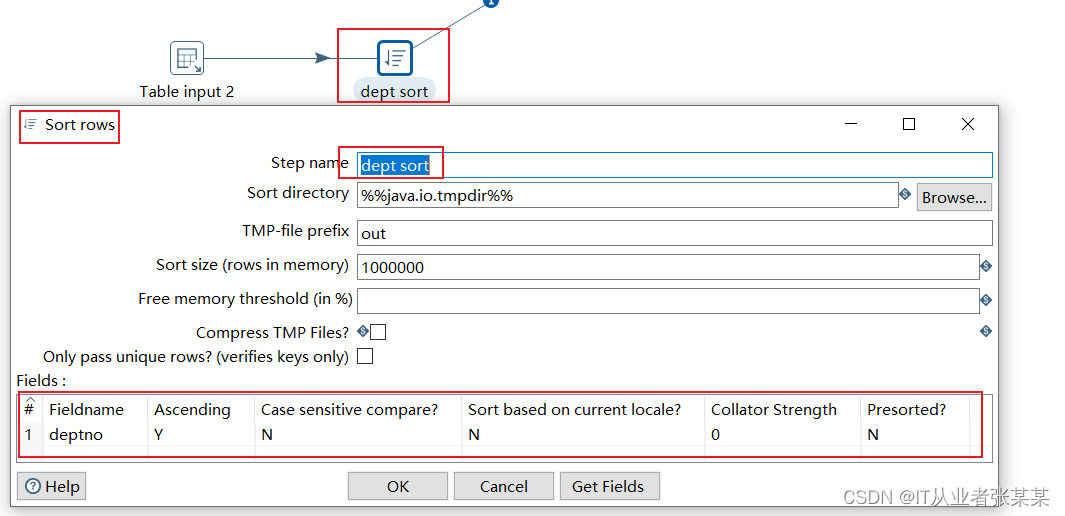
4)dept sorts 步骤项设置
本步骤用于对hive中的dept数据进行排序:
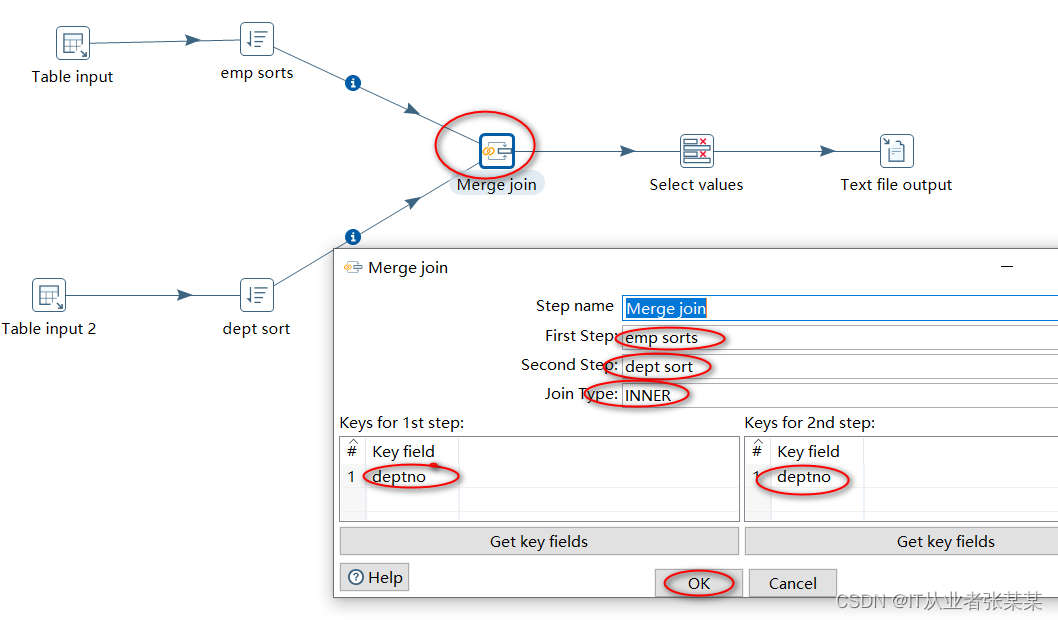
5)Merge join操作
本步骤用于将经过排序的两张表中的数据执行join操作,join选择内链接
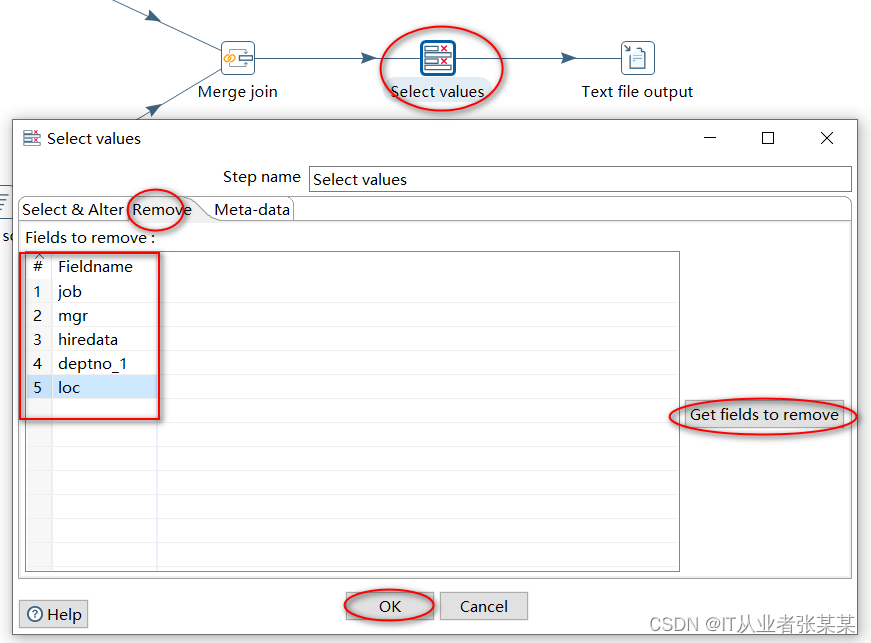
6)select values步骤项设置
选择字段,本步骤主要用于移除部分字段
7)text file output步骤项设置
在open file中选择hdfs文件系统,并进行相关配置。
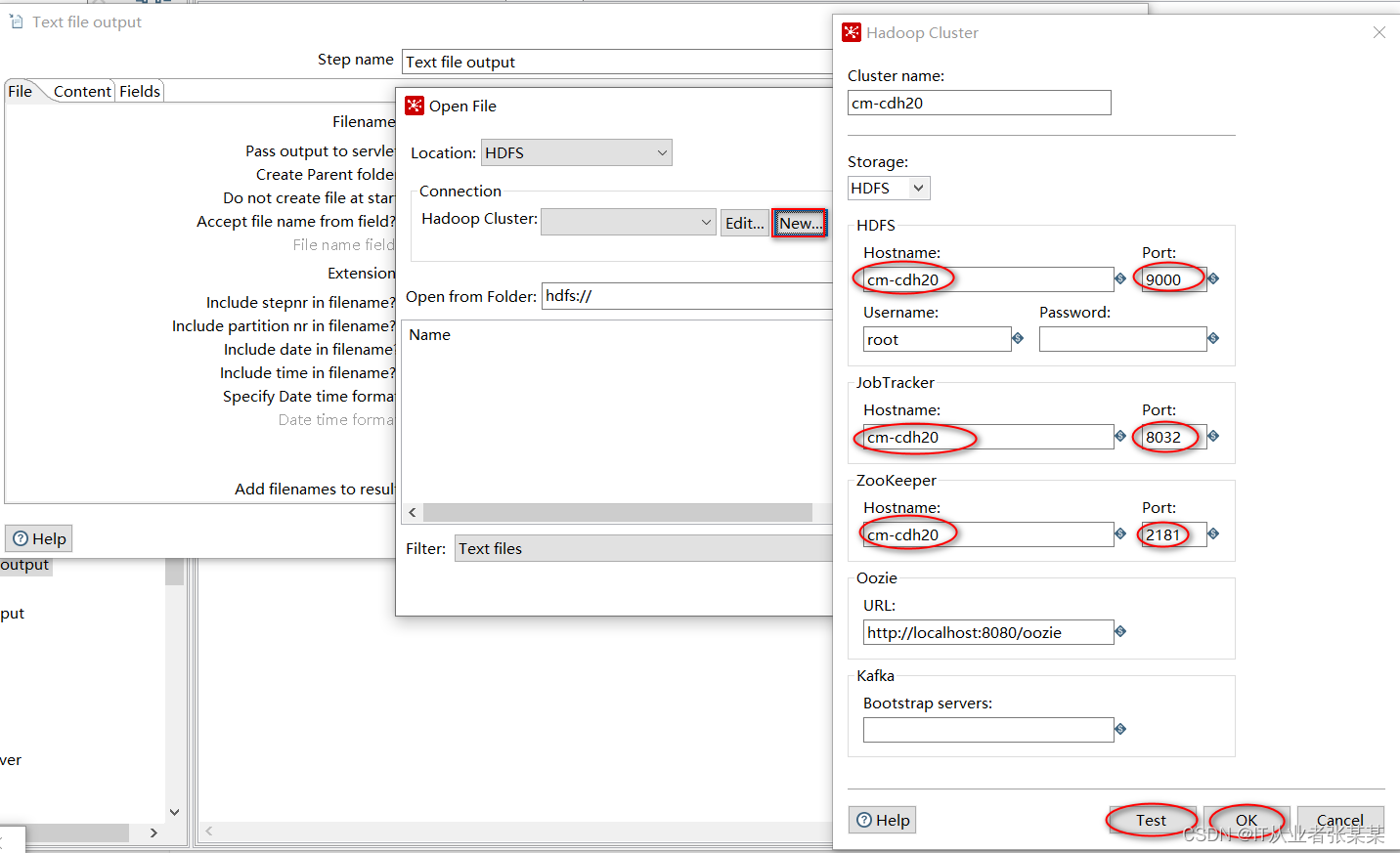
配置完毕后,进行测试,测试结果如下:
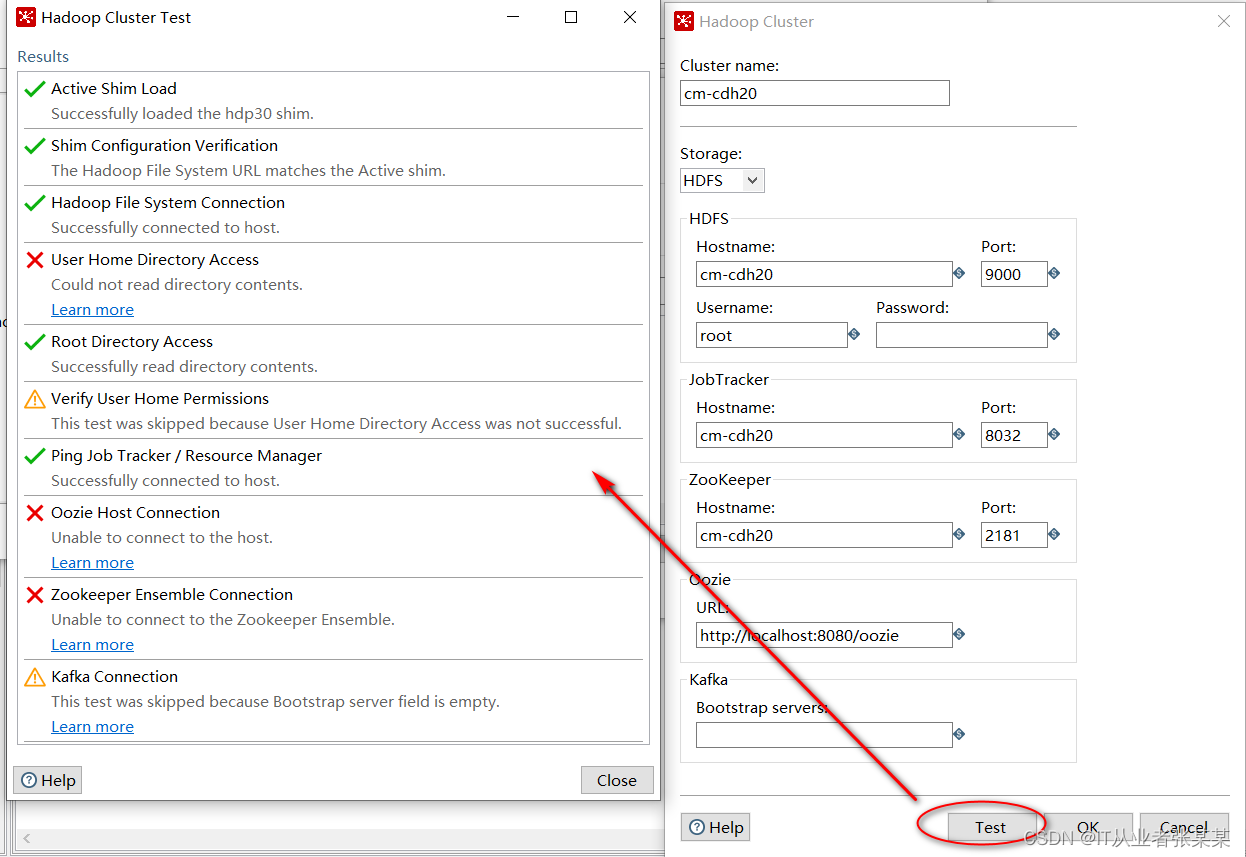
从测试结果可以看出,zk没有开,开启了hdfs,和yarn
测试通过后,点击ok,选择hdfs上的路径。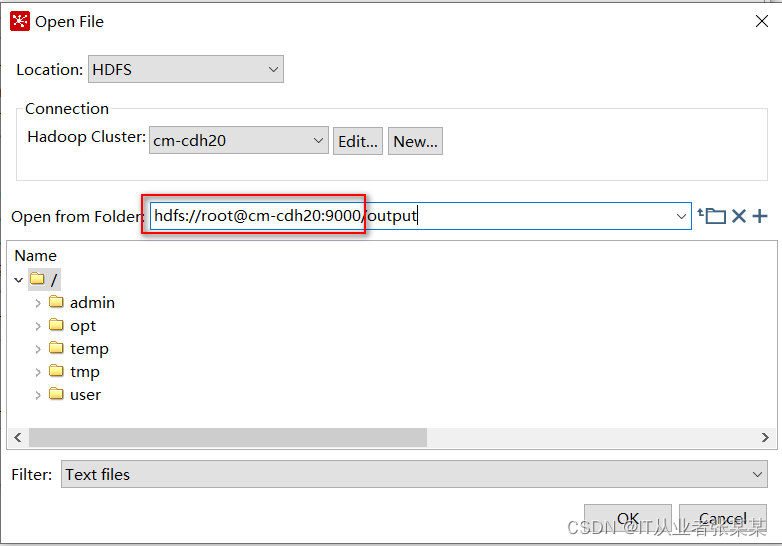
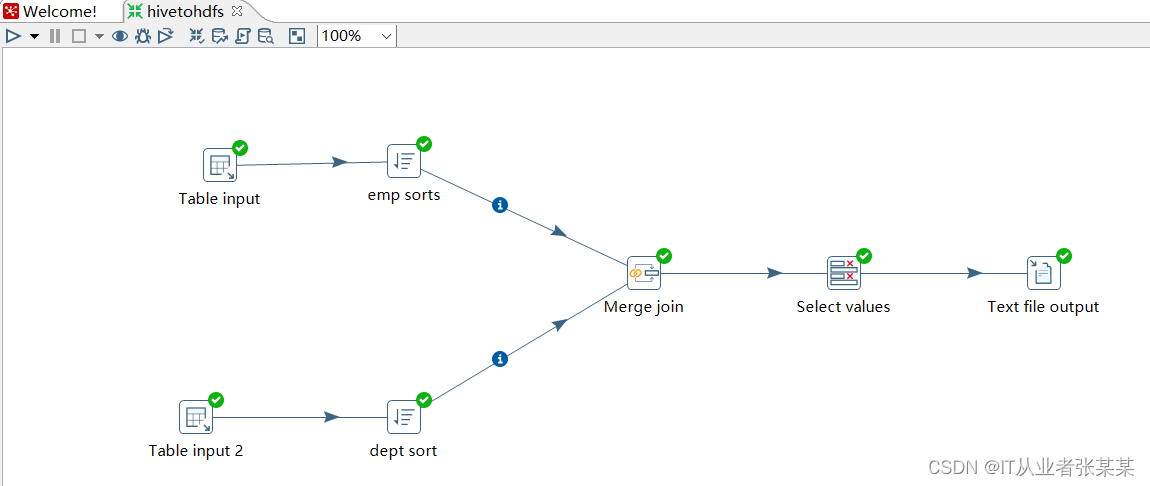
8)运行转换,并查看结果
运行示意图:
进入到hdfs所在的机器上,查看输出结果如下:

3 读取HDFS写入HBase
需求:将hdfs中sal小于110000的数据保存在hbase中
3.1工作流设计
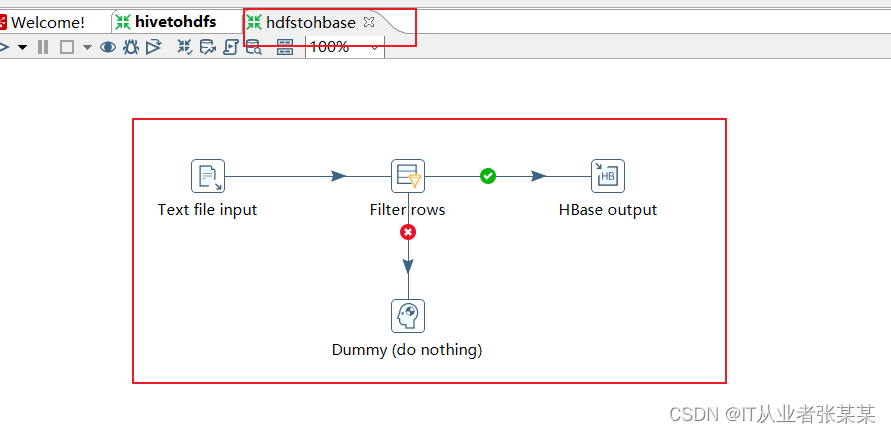
3.2启动HBase
#开启hbase start-hbase.sh #进入hbase shell #建表 create 'emp','info'
3.3具体转换设计
1)转换设计为:
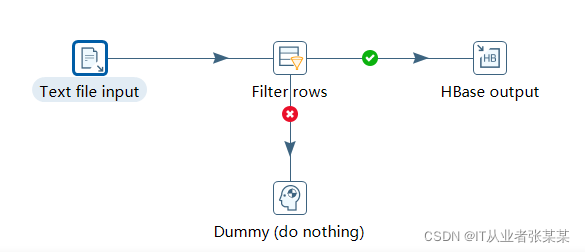
2)text file input步骤设计
这一步骤与上一案例中的基本类似
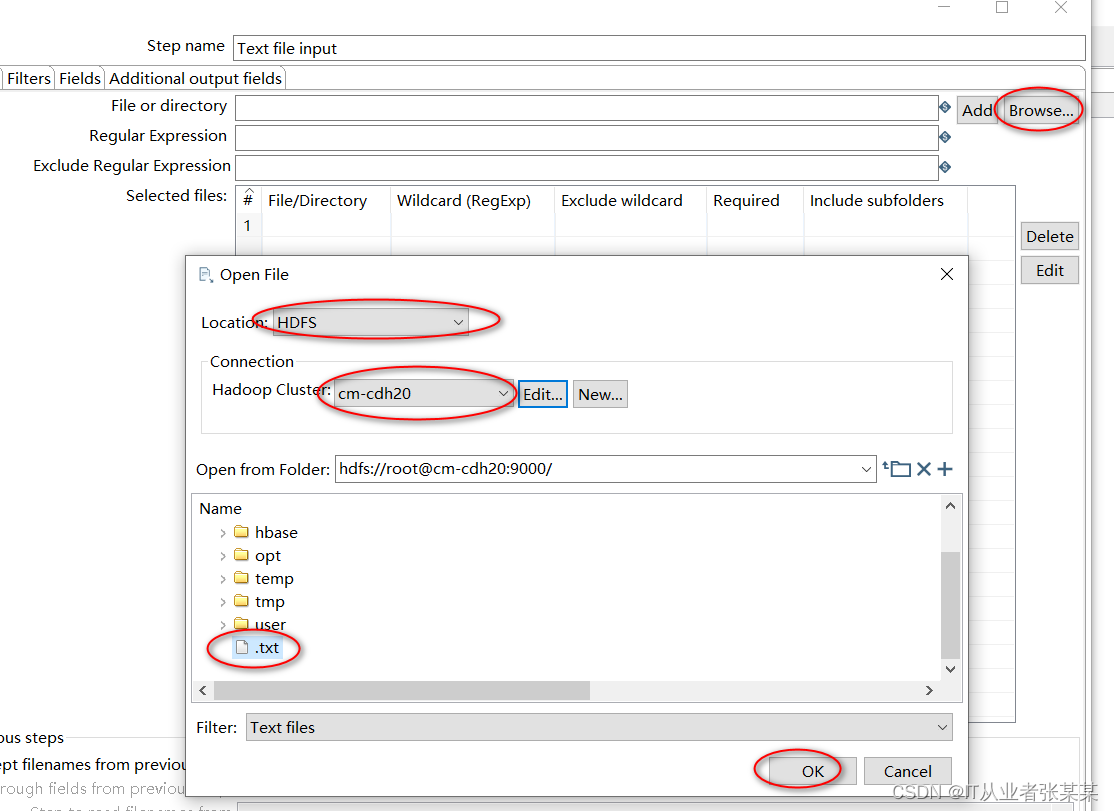
选择hdfs的.txt文件
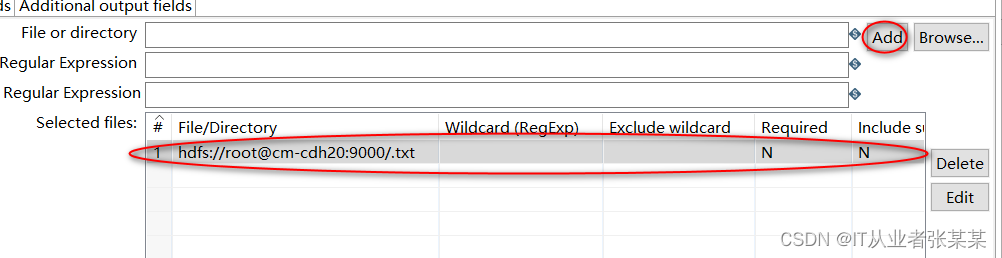
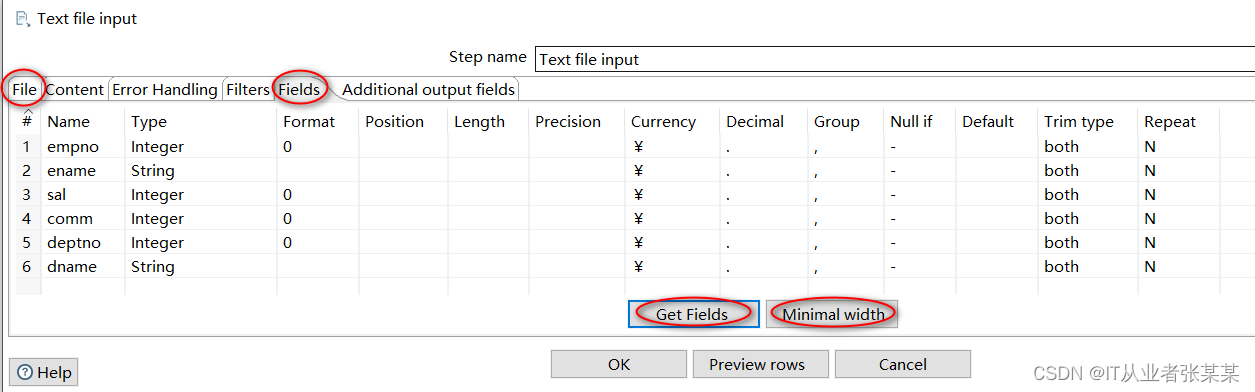
.txt中的数据就是emp表的数据,如下
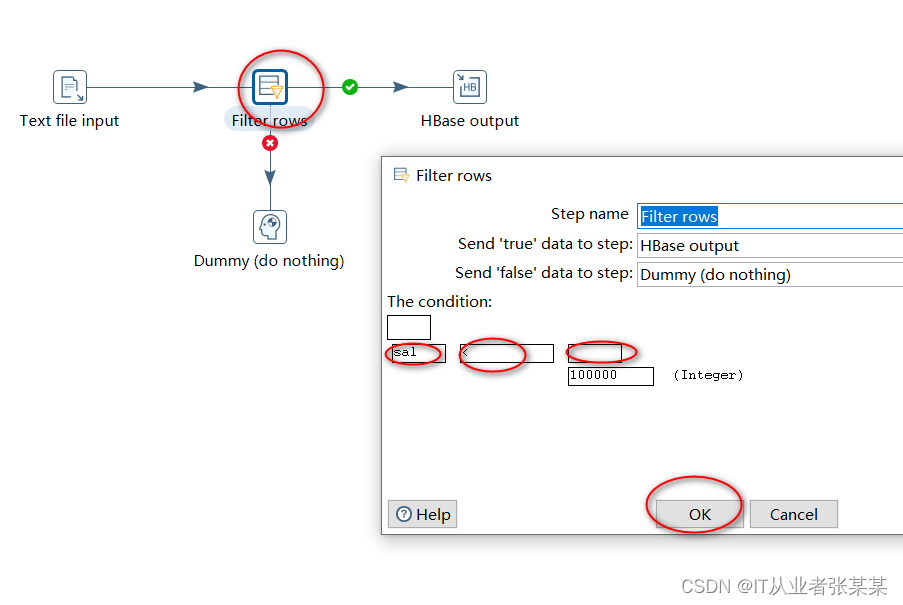
2)filter rows步骤设计
通过filter rows过滤出工作小于100000的员工
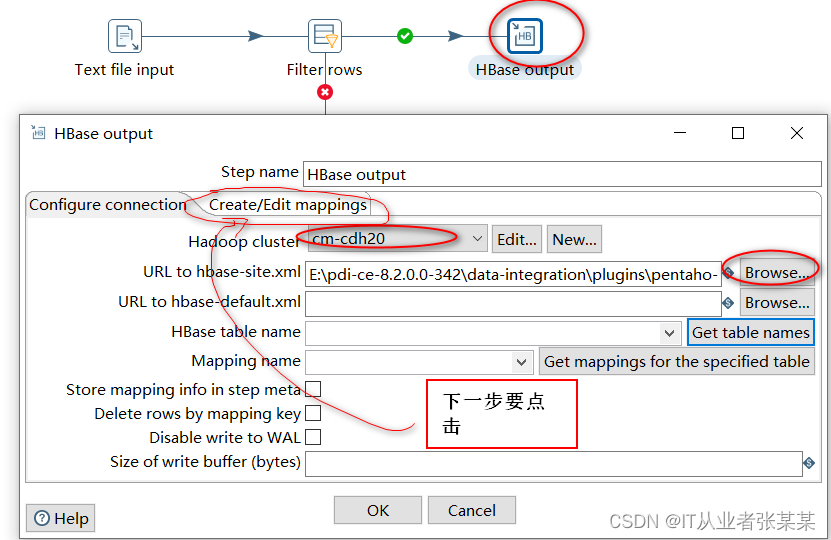
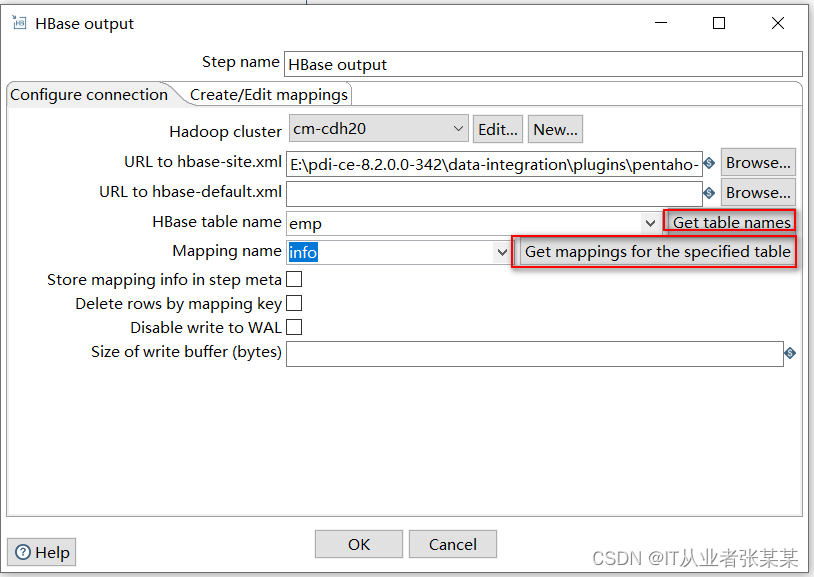
3)HBase output
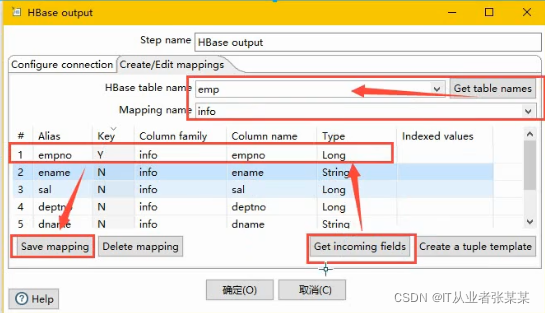
创建映射:选择字符串在hbase shell端不乱码
再次配置hbase链接
如果出现:
NoSuchColumnFamilyException: Column family table does not exist in region hbase:meta,,1.1588230740 in table 'hbase:meta'
原因:是因为hbase服务端版本过低,客户端版本不能高于服务端版本
解决办法:选择hdp26
查看hbase,并解决命令行查看中文乱码问题
scan 'emp', {FORMATTER => 'toString'} scan 'emp', {FORMATTER_CLASS => 'org.apache.hadoop.hbase.util.Bytes', FORMATTER => 'toString'}
总结
本文主要描述了基于kettle实现从hive读取数据写入到hdfs,同时实现从HDFS读取数据写入HBase中的完整流程,同时为便于读者能根据本博客实现完整的实验,还参考了部分博客,增加了mysql和hive的安装过程,并针对自己安装过程中遇到的问题,进行了记录。


