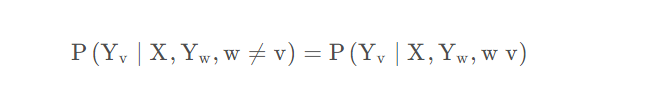现实任务涉及多个因素(变量),并且因素之间存在依赖关系。概率图模型(Probabilistic Graphical Model,PGM)为表示、学习这种依赖关系提供了一个强大的框架。
1. 定义
图(graph)是由节点(node)和边组成的集合,记作G = ( V , E ) G=(V,E)G=(V,E),其中V VV和E EE分别表示节点和边的集合,节点v ∈ V v \in Vv∈V,边e ∈ E e \in Ee∈E。
(1)概率图模型
概率图模型(PGM,Probabilistic Graphical Model)是由图表示的概率分布。
设有联合概率分布P ( Y ) ,Y 是一组随机变量,图G = ( V , E ) 表示概率分布P ( Y ) ,即在图G 中,节点v ∈ V表示一个随机变量Y v,Y = ( Y v ) v ∈ V ;边e ∈ E表示随机变量之间的概率依赖关系。
概率图模型相比于其他学习算法的优势在于可以利用图结构来将已知信息带入到知识网络中。
根据边的性质不同,概率图模型分为两类:
有向图模型或贝叶斯网络(Bayesian network):使用有向无环图表示变量间的因果(依赖)关系
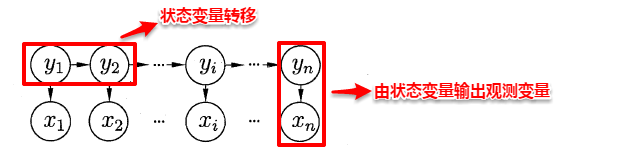
包括隐马尔可夫模型(HMM)及卡尔曼滤波器(Kalman filter)
无向图模型或马尔可夫网(Markov networkd):使用无向图(指边没有方向的图)表示变量间的相关关系
包括条件随机场(CRF)及波尔兹曼机(Boltzmann machine)

(2) 概率图模型的演变过程
横向:由点到线(序列结构)、到面(图结构)
以朴素贝叶斯模型为基础的隐马尔可夫模型用于处理线性序列问题,有向图模型用于解决一般图问题;
以逻辑回归模型(即自然语言处理中ME模型)为基础的线性链式条件随机场用于解决“线式”序列问题,通用条件随机场用于解决一般图问题。
纵向:在一定条件下生成式模型(generativemodel)转变为判别式模型(discriminative model)
朴素贝叶斯模型演变为逻辑回归模型
隐马尔可夫模型演变为线性链式条件随机场
生成式有向图模型演变为通用条件随机场。

(3)概率图模型的三个基本问题:
- 表示问题:对于一个概率模型,如何通过图结构来描述变量之间的依赖关系。
- 推断问题:在已知部分变量时算其它变量的后验概率分布。
- 学习问题:图模型的学习包括图结构的学习和参数的学习。
2. 概率有向图模型
概率有向图使用有向无环图表示变量之间的关系。
变量X1 X2 X 3 的一个联合概率分布:

对应的有向图如下所示:

每个变量对应一个结点,如果存在从结点X1 到结点 X2的有向边,则X1 是结点 X2的父结点,结点X2 是结点X1 的子结点。
每个条件概率对应一条有向边,起点是条件概率中条件随机变量对应的结点
K个变量的联合概率分布:

对应的有向图如下所示:

 的概率图如下
的概率图如下

图中所有结点上定义的联合概率分布由每个结点上的条件概率分布的积表示,每个条件概率分布的条件都是图中结点的父结点所对应的变量。
一个有K 个结点的图,联合概率

pa k表示结点x k 的父结点的集合p a k ⊆ { x 1 , x 2 , . . . , x k − 1 }
此公式表示有向图模型的联合概率分布的分解属性。
有向图不能存在有向环。
3. 概率无向图模型
3.1 基本概念
(1) 成对马尔可夫性
设u和v 是无向图G GG中任意两个没有边连接的结点,结点u 和v 分别对应随机变量Y u和Y v 。其他所有结点为O (集合),对应的随机变量组是 Y O 。成对马尔可夫性是指给定随机变量组Y O的条件下随机变量 Y u和Y v条件独立,即没有直连边的任意两个节点是独立的。

(2)局部马尔可夫性
设v ∈ V v 是无向图 G 中任意一个结点,W 是与$ v$ 有边连接的所有结点,O 是v , W 以外的其他所有结点。v 、W 、O 表示的随机变量分别是
局部马尔可夫性是指在给定随机变量组 Y W 的条件下随机变量 v 与随机变量组 Y O 是独立的


(3)全局马尔可夫性
设结点集合A , B 是在无向图G 中被结点集合 C 分开的任意结点集合。从结点集合Az中的点到达结点集合B 必须经过结点集合C。结点集合 $A,B , C $所对应的随机变量组分别是 Y A , Y B , Y C 全局马尔可夫性是指给定随机变量组条件下随机变量组 Y A和Y B 条件独立。


概率无向图模型定义
设有联合概率分布P ( Y ),由无向图G = ( V , E ) 表示概率分布P ( Y ) P(Y)P(Y),在图G中,节点v ∈ V 表示随机变量,边e ∈ E 表示随机变量之间的概率依赖关系,如果联合概率分布$ P(Y) $满足成对、局部或全局马尔可夫性,就称联合概率分布为概率无向图模型(probabilistic undirected graphical model)、马尔可夫随机场(Markov random field)或马尔可夫网络(Markov Network)
3.2 因子分解
(1)团(clique):无向图G GG中任何两个结点均有边连接的结点子集
**(2)最大团(maximal clique) ** :若$ C$ 是无向图$ G$ 的一个团,并且不能再加进任何一个$ G$ 的结点使其成为一个更大的团,则称C为最大团

由4个结点组成的无向图,共有7个团:

两个最大团{ Y 1 , Y 2 , Y 3 } , { Y 2 , Y 3 , Y 4 }
(3)因子分解 :将概率无向图模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作。
(4) Hammersley-Clifford定理
如果一个分部P ( Y ) > 0 满足无向图G 中的局部马尔可夫性质,当且仅当P ( Y ) 可以表示为一系列定义在最大团上的非负函数的乘积形式,即

其中,Q 为G 中的最大团集合。
Ψ Q ( Y Q ) > 0 是定义在团C 上的势能函数(potential function)
Z 是配分函数(partition function),用来将乘积归一化为概率形式:

(5)吉布斯分布(Gibbs distribution)

根据HC定理,概率无向图模型和吉布斯分布是一致的。吉布斯分布一定满足马尔可夫随机场的条件独立性质,并且马尔可夫随机场的概率分布一定可以表示成吉布斯分布。
上图联合概率分布可以写成:

(6) 玻尔兹曼分布(Boltzmann Distribution)
势能函数通常定义为指数函数:

这种形式的分布又被称为波尔兹曼分布(Boltzmann Distribution)。
任何一个无向图模型都可以用上述公式来表示其联合概率分布。